Shardingsphere(5.0.0.beta)源码学习-总览
shardingsphere作为极为优秀的开源分布式数据库解决方案,通过阅读源码可以学到很多软件设计与开发的知识。
本次我继续按照之前读源码的方式从整体到细节,带着问题读源码的方式记录这次深入学习 shardingsphere的过程。
源码版本
- 5.0.0.beta 官方文档
- 源码地址 https://github.com/apache/shardingsphere/tree/5.0.0-beta
项目结构
先大概理解各个模块的主要功能点
| 一级目录 | 说明 |
|---|---|
| examples | 各种使用例子 |
| shardingsphere-agent | 监控, 对接apm,链路追踪 |
| shardingsphere-db-protocol | 数据库协议 |
| shardingsphere-distribution | 相关打包发步用 |
| shardingsphere-distsql-parser | distsql新功能: ShardingSphere 特有的内置 SQL 语言,提供了标准 SQL 之外的增量功能操作能力。 |
| shardingsphere-features | 常用功能shardingsphere-db-discovery 基于MGR主从切换的功能shardingsphere-encrypt 加解密shardingsphere-readwrite-splitting 读写分离 **重点**shardingsphere-shadow 影子库shardingsphere-sharding 分库分表 **重点** |
| shardingsphere-governance | 数据治理:结合注册中心,提供给前端页面使用 |
| shardingsphere-infra | 引擎内核:shardingsphere-infra-authority proxy的权限控制shardingsphere-infra-binder sql解析后的结果绑定封装 SQLStatement封装为各类上下文contextshardingsphere-infra-common 重要的实体类及工具 的元数据metadata,SPI,yaml工具,rule接口等shardingsphere-infra-context 上下文相关shardingsphere-infra-datetime 时间服务shardingsphere-infra-executor 执行器引擎 **重点**shardingsphere-infra-merge 归并引擎**重点**shardingsphere-infra-optimize 优化引擎**重点**shardingsphere-infra-parser 解析引擎**重点**shardingsphere-infra-rewrite 改写引擎**重点**shardingsphere-infra-route 路由引擎**重点** |
| shardingsphere-jdbc | jdbc核心功能:增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。装饰器模式,对原生的DataSource,Connection,Statement(PrepareStatement),ResultSet进行包装, |
| shardingsphere-proxy | 透明化的数据库代理提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持 |
| shardingsphere-scaling | 数据迁移相关:弹性伸缩 |
| shardingsphere-sql-parser | sql解析器:antlr4 词法语法解析出SqlStatement,提供各类数据库的方言实现。SQL 解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标 |
| shardingsphere-test | 测试引擎 |
| shardingsphere-transaction | 事务:整合现有的成熟事务方案,本地事务、两阶段事务(XA)和柔性事务(Seata AT 事务)提供统一的分布式事务接口 |
对于重点核心内容有个大致认识,后面再单独分模块分析。
代码分析
shardingsphere-jdbc是用的最多的接入方式,以 shardingsphere-jdbc的insert一条数据为例,先过一遍流程。
INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
分析入口
使用org.apache.shardingsphere.example.sharding.raw.jdbc.YamlConfigurationExampleMain 的分库分表示例,插入数据。
public final class YamlConfigurationExampleMain {
private static ShardingType shardingType = ShardingType.SHARDING_DATABASES_AND_TABLES;
public static void main(final String[] args) throws SQLException, IOException {
// 初始化得到的DataSource为ShardingSphereDataSource
DataSource dataSource = YamlDataSourceFactory.newInstance(shardingType);
ExampleExecuteTemplate.run(getExampleService(dataSource));
}
...
}
YamlDataSourceFactory.newInstance(shardingType)调用ShardingSphereDataSourceFactory.createDataSource得到ShardingSphereDataSource,可以看到ShardingSphereDataSource是对JDBC规范DataSource的实现。
同样,后续用的Connection、Statement、PrepareStatement都有对应的ShardingConnection、ShardingStatment、ShardingPreparedStatement的实现。
public final class ShardingSphereDataSourceFactory {
...
public static DataSource createDataSource(final Map<String, DataSource> dataSourceMap, final Collection<RuleConfiguration> configurations, final Properties props) throws SQLException {
return new ShardingSphereDataSource(dataSourceMap, configurations, props);
}
...
}
jdbc
shardingsphere-jdbc下shardingsphere-jdbc-core中定义了jdbc规范的ShardingSphere实现
AbstractXXXAdapter对jdbc规范接口做一次适配
都继承了父类AbstractUnsupportedOperationXxx : 各个数据库厂家对jdbc规范没有完整实现,ShardingSphere对这些没实现方法统一在
AbstractUnsupportedOperationXxx 中抛出不支持的异常,指明用户不可以使用。
org.apache.shardingsphere.driver.jdbc.core.datasource.ShardingSphereDataSource
public final class ShardingSphereDataSource extends AbstractUnsupportedOperationDataSource implements AutoCloseable {
private final MetaDataContexts metaDataContexts;
private final TransactionContexts transactionContexts;
...
@Override
public ShardingSphereConnection getConnection() {
return new ShardingSphereConnection(getDataSourceMap(), metaDataContexts, transactionContexts, TransactionTypeHolder.get());
}
@Override
public ShardingSphereConnection getConnection(final String username, final String password) {
return getConnection();
}
...
}
org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection
public final class ShardingSphereConnection extends AbstractConnectionAdapter implements ExecutorJDBCManager {
// 数据源map
private final Map<String, DataSource> dataSourceMap;
private final MetaDataContexts metaDataContexts;
//事务类型 LOCAL, XA, BASE;
private final TransactionType transactionType;
private final ShardingTransactionManager shardingTransactionManager;
...
@Override
public PreparedStatement prepareStatement(final String sql, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) throws SQLException {
return new ShardingSpherePreparedStatement(this, sql, resultSetType, resultSetConcurrency, resultSetHoldability);
}
...
@Override
public Statement createStatement(final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {
return new ShardingSphereStatement(this, resultSetType, resultSetConcurrency, resultSetHoldability);
}
...
}
org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement
public final class ShardingSpherePreparedStatement extends AbstractPreparedStatementAdapter {
...
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious();
executionContext = createExecutionContext();
List<QueryResult> queryResults = executeQuery0();
// 执行的查询结构通过归并引擎归并
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingSphereResultSet(getResultSetsForShardingSphereResultSet(), mergedResult, this, executionContext);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
@Override
public int executeUpdate() throws SQLException {
...
}
@Override
public boolean execute() throws SQLException {
...
}
// 调用归并引擎
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingSphereMetaData metaData = metaDataContexts.getDefaultMetaData();
MergeEngine mergeEngine = new MergeEngine(
metaDataContexts.getDefaultMetaData().getResource().getDatabaseType(), metaData.getSchema(), metaDataContexts.getProps(), metaData.getRuleMetaData().getRules());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
...
}
执行流程
再接着调试栈来看
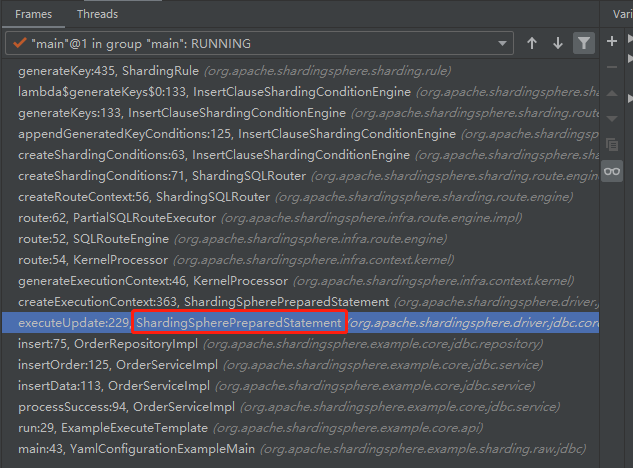
执行流程为
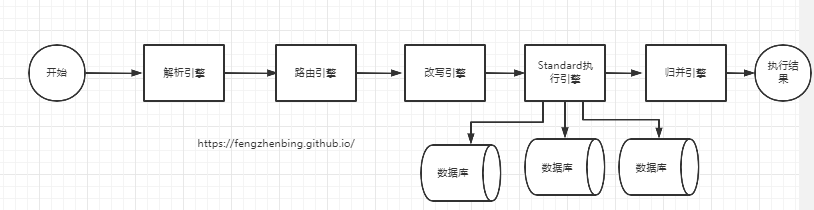
下面简单分析:
public final class ShardingSpherePreparedStatement extends AbstractPreparedStatementAdapter {
private ShardingSpherePreparedStatement(final ShardingSphereConnection connection, final String sql,
final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability, final boolean returnGeneratedKeys) throws SQLException {
....
// 各种初始化省略
// 敲黑板: 1, 使用解析器引擎解析sql语句,得到结果sqlStatement。 SqlStatement封装了sql解析后各类AST节点(DDL,DML,DCL...)后面细讲
ShardingSphereSQLParserEngine sqlParserEngine = new ShardingSphereSQLParserEngine(DatabaseTypeRegistry.getTrunkDatabaseTypeName(metaDataContexts.getDefaultMetaData().getResource().getDatabaseType()));
sqlStatement = sqlParserEngine.parse(sql, true);
...
// sql执行器 RawExecutor
rawExecutor = new RawExecutor(metaDataContexts.getExecutorEngine(), connection.isHoldTransaction(), metaDataContexts.getProps());
....
// 各种初始化省略
}
...
@Override
public int executeUpdate() throws SQLException {
try {
clearPrevious();
// 创建执行的上下文,创建过程中完成了路由的解析,sQL改写真实sql,
executionContext = createExecutionContext();
if (metaDataContexts.getDefaultMetaData().getRuleMetaData().getRules().stream().anyMatch(each -> each instanceof RawExecutionRule)) {
Collection<ExecuteResult> executeResults = rawExecutor.execute(createRawExecutionGroupContext(), executionContext.getSqlStatementContext(), new RawSQLExecutorCallback());
accumulate(executeResults);
}
// 下面会调用执行
ExecutionGroupContext<JDBCExecutionUnit> executionGroupContext = createExecutionGroupContext();
cacheStatements(executionGroupContext.getInputGroups());
// DriverJDBCExecutor会调用执行引擎执行 driverJDBCExecutor.executeUpdate下面会简单分析
return driverJDBCExecutor.executeUpdate(executionGroupContext,
executionContext.getSqlStatementContext(), executionContext.getRouteContext().getRouteUnits(), createExecuteUpdateCallback());
} finally {
clearBatch();
}
}
...
// 创建执行的上下文
private ExecutionContext createExecutionContext() {
// 创建逻辑SQL
LogicSQL logicSQL = createLogicSQL();
// SQLCheckEngine检查SQL的是否合法
SQLCheckEngine.check(logicSQL.getSqlStatementContext().getSqlStatement(), logicSQL.getParameters(),
metaDataContexts.getDefaultMetaData().getRuleMetaData().getRules(), DefaultSchema.LOGIC_NAME, metaDataContexts.getMetaDataMap(), null);
//内核处理器生成执行上下文
ExecutionContext result = kernelProcessor.generateExecutionContext(logicSQL, metaDataContexts.getDefaultMetaData(), metaDataContexts.getProps());
findGeneratedKey(result).ifPresent(generatedKey -> generatedValues.addAll(generatedKey.getGeneratedValues()));
return result;
}
// 创建逻辑SQL
private LogicSQL createLogicSQL() {
List<Object> parameters = new ArrayList<>(getParameters());
ShardingSphereSchema schema = metaDataContexts.getDefaultMetaData().getSchema();
SQLStatementContext<?> sqlStatementContext = SQLStatementContextFactory.newInstance(schema, parameters, sqlStatement);
return new LogicSQL(sqlStatementContext, sql, parameters);
}
...
}
再看内核处理器如何生成执行上下文
org.apache.shardingsphere.infra.context.kernel.KernelProcessor
/**
* Kernel processor. 内核处理器
*/
public final class KernelProcessor {
/**
* Generate execution context.
* 创建执行上下文
* @param logicSQL logic SQL
* @param metaData ShardingSphere meta data
* @param props configuration properties
* @return execution context
*/
public ExecutionContext generateExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
//2 使用路由引擎创建路由
RouteContext routeContext = route(logicSQL, metaData, props);
//3 使用改写引擎改写出真实执行的sql
SQLRewriteResult rewriteResult = rewrite(logicSQL, metaData, props, routeContext);
//4 创建执行上下文
ExecutionContext result = createExecutionContext(logicSQL, metaData, routeContext, rewriteResult);
// 日志
logSQL(logicSQL, props, result);
return result;
}
// 使用路由引擎创建路由 SQLRouteEngine(...).route(..)
private RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
return new SQLRouteEngine(metaData.getRuleMetaData().getRules(), props).route(logicSQL, metaData);
}
// SQLRewriteEntry改写引擎
private SQLRewriteResult rewrite(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props, final RouteContext routeContext) {
return new SQLRewriteEntry(
metaData.getSchema(), props, metaData.getRuleMetaData().getRules()).rewrite(logicSQL.getSql(), logicSQL.getParameters(), logicSQL.getSqlStatementContext(), routeContext);
}
// 创建执行上下文
private ExecutionContext createExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final RouteContext routeContext, final SQLRewriteResult rewriteResult) {
return new ExecutionContext(logicSQL.getSqlStatementContext(), ExecutionContextBuilder.build(metaData, rewriteResult, logicSQL.getSqlStatementContext()), routeContext);
}
private void logSQL(final LogicSQL logicSQL, final ConfigurationProperties props, final ExecutionContext executionContext) {
if (props.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(logicSQL, props.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), executionContext);
}
}
}
解析引擎
路由引擎
@RequiredArgsConstructor
public final class SQLRouteEngine {
private final Collection<ShardingSphereRule> rules;
private final ConfigurationProperties props;
/**
* Route SQL.
*
* @param logicSQL logic SQL
* @param metaData ShardingSphere meta data
* @return route context
*/
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
SQLRouteExecutor executor = isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement()) ? new AllSQLRouteExecutor() : new PartialSQLRouteExecutor(rules, props);
// 进行路由计算,生成路由结果上下文RouteContext
return executor.route(logicSQL, metaData);
}
// TODO use dynamic config to judge UnconfiguredSchema
private boolean isNeedAllSchemas(final SQLStatement sqlStatement) {
return sqlStatement instanceof MySQLShowTablesStatement;
}
}
SQL改写
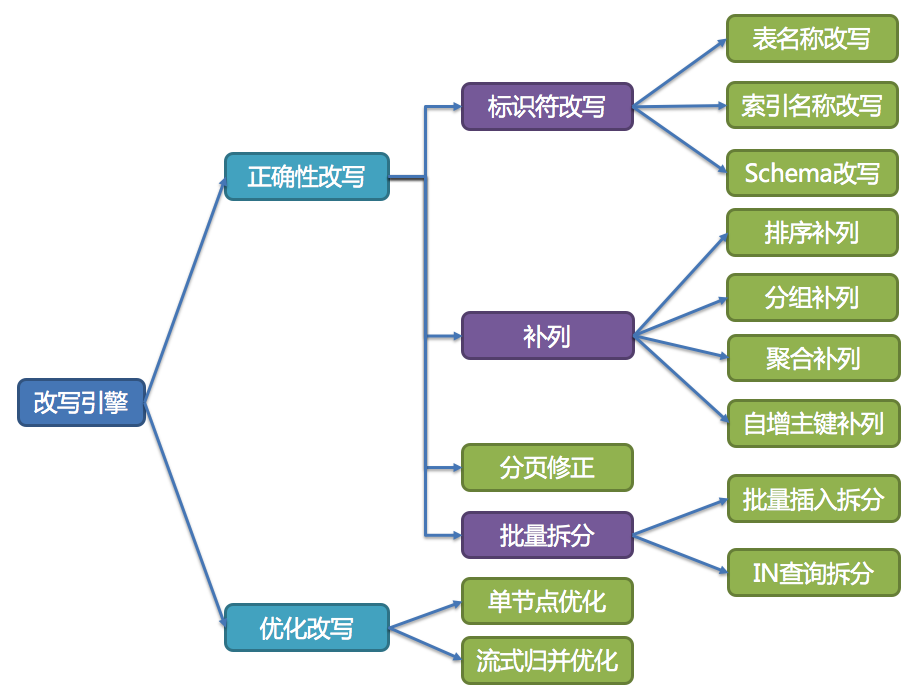
加密的SQL改写
影子库SQL改写
分片的SQL改写
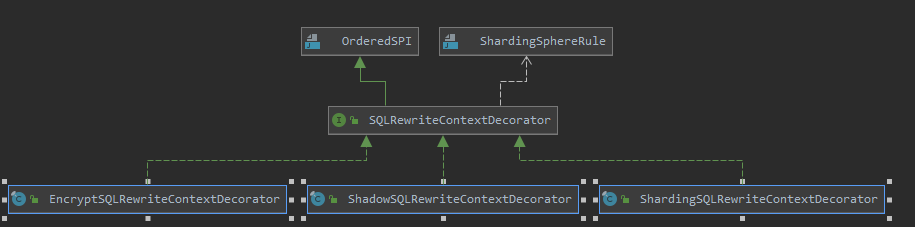
执行引擎
将路由和改写完成之后的真实 SQL 安全且高效发送到底层数据源执行。
public final class DriverJDBCExecutor {
...
/**
* Execute update.
*
* @param executionGroupContext execution group context
* @param sqlStatementContext SQL statement context
* @param routeUnits route units
* @param callback JDBC executor callback 回调
* @return effected records count
* @throws SQLException SQL exception
*/
public int executeUpdate(final ExecutionGroupContext<JDBCExecutionUnit> executionGroupContext,
final SQLStatementContext<?> sqlStatementContext, final Collection<RouteUnit> routeUnits, final JDBCExecutorCallback<Integer> callback) throws SQLException {
try {
// 执行引擎初始化
ExecuteProcessEngine.initialize(sqlStatementContext, executionGroupContext, metaDataContexts.getProps());
List<Integer> results = jdbcLockEngine.execute(executionGroupContext, sqlStatementContext, routeUnits, callback);
int result = isNeedAccumulate(metaDataContexts.getDefaultMetaData().getRuleMetaData().getRules(), sqlStatementContext) ? accumulate(results) : results.get(0);
ExecuteProcessEngine.finish(executionGroupContext.getExecutionID());
return result;
} finally {
ExecuteProcessEngine.clean();
}
}
...
}
归并引擎
对于查询类,有结果会使用归并引擎合并结果 MergeEngine(..).merge(..)
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
org.apache.shardingsphere.infra.merge.MergeEngine
public final class MergeEngine {
static {
ShardingSphereServiceLoader.register(ResultProcessEngine.class);
}
private final DatabaseType databaseType;
private final ShardingSphereSchema schema;
private final ConfigurationProperties props;
@SuppressWarnings("rawtypes")
private final Map<ShardingSphereRule, ResultProcessEngine> engines;
public MergeEngine(final DatabaseType databaseType, final ShardingSphereSchema schema, final ConfigurationProperties props, final Collection<ShardingSphereRule> rules) {
this.databaseType = databaseType;
this.schema = schema;
this.props = props;
engines = OrderedSPIRegistry.getRegisteredServices(rules, ResultProcessEngine.class);
}
/**
* Merge.
*
* @param queryResults query results
* @param sqlStatementContext SQL statement context
* @return merged result
* @throws SQLException SQL exception
*/
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
//生成合并结果集
Optional<MergedResult> mergedResult = executeMerge(queryResults, sqlStatementContext);
//对合并结果集装饰处理
Optional<MergedResult> result = mergedResult.isPresent() ? Optional.of(decorate(mergedResult.get(), sqlStatementContext)) : decorate(queryResults.get(0), sqlStatementContext);
return result.orElseGet(() -> new TransparentMergedResult(queryResults.get(0)));
}
@SuppressWarnings({"unchecked", "rawtypes"})
private Optional<MergedResult> executeMerge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
for (Entry<ShardingSphereRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultMergerEngine) {
ResultMerger resultMerger = ((ResultMergerEngine) entry.getValue()).newInstance(databaseType, entry.getKey(), props, sqlStatementContext);
// ResultMerger进行合并
return Optional.of(resultMerger.merge(queryResults, sqlStatementContext, schema));
}
}
return Optional.empty();
}
@SuppressWarnings({"unchecked", "rawtypes"})
private MergedResult decorate(final MergedResult mergedResult, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
MergedResult result = null;
for (Entry<ShardingSphereRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultDecoratorEngine) {
ResultDecorator resultDecorator = ((ResultDecoratorEngine) entry.getValue()).newInstance(databaseType, schema, entry.getKey(), props, sqlStatementContext);
result = null == result ? resultDecorator.decorate(mergedResult, sqlStatementContext, entry.getKey()) : resultDecorator.decorate(result, sqlStatementContext, entry.getKey());
}
}
return null == result ? mergedResult : result;
}
@SuppressWarnings({"unchecked", "rawtypes"})
private Optional<MergedResult> decorate(final QueryResult queryResult, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
MergedResult result = null;
for (Entry<ShardingSphereRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultDecoratorEngine) {
ResultDecorator resultDecorator = ((ResultDecoratorEngine) entry.getValue()).newInstance(databaseType, schema, entry.getKey(), props, sqlStatementContext);
result = null == result ? resultDecorator.decorate(queryResult, sqlStatementContext, entry.getKey()) : resultDecorator.decorate(result, sqlStatementContext, entry.getKey());
}
}
return Optional.ofNullable(result);
}
}
ResultMerger
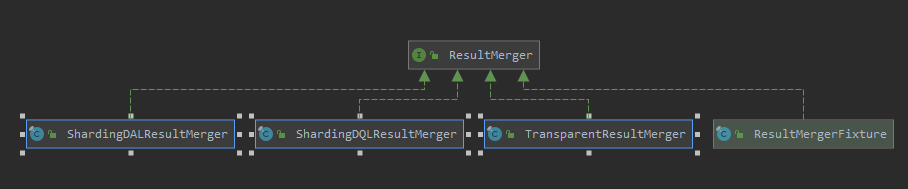
- 以上对整个流程中各个关键节点进行简单分析,后续对每个节点做详细学习